The Requirement
We had a requirement to return both parent and child documents in Solr Join Query.
Solr Join Query doesn't return docs from parent documents: Solr Join Query
Compared To SQL
To support this, We have to change Solr's code to support the syntax like below:
q={!join from=fromField to=toField includeParent=true childfq=childfq}parentQuery
includeParent=true means it will return parent docs. Default value is false.
childfq is a query that will filter child docs.
Changing JoinQParserPlugin
First, we will change org.apache.solr.search.JoinQParserPlugin.createParser to parse local parameter.
We need change org.apache.solr.search.JoinQuery.JoinQueryWeight.getDocSet(), before return result: filter child docs if childfq is not null, include parent docs if includeParent is true.
Also we have to change JoinQuery's equals and hashCode method to consider includeParent and childfq parameters.
As we only use this feature in single core mode, not in shards(multiple cores) mode, so we have not tested whether this works in shards mode.
References
Solr Join Query
Solr Other Parsers
We had a requirement to return both parent and child documents in Solr Join Query.
Solr Join Query doesn't return docs from parent documents: Solr Join Query
Compared To SQL
For people who are used to SQL, it's important to note that Joins in Solr are not really equivalent to SQL Joins because no information about the table being joined "from" is carried forward into the final result. A more appropriate SQL analogy would be an "inner query".
This Solr request...
/solr/collection1/select ? fl=xxx,yyy & q={!join from=inner_id to=outer_id}zzz:vvv
Is comparable to this SQL statement...
SELECT xxx, yyy FROM collection1 WHERE outer_id IN (SELECT inner_id FROM collection1 where zzz = "vvv")
To support this, We have to change Solr's code to support the syntax like below:
q={!join from=fromField to=toField includeParent=true childfq=childfq}parentQuery
includeParent=true means it will return parent docs. Default value is false.
childfq is a query that will filter child docs.
Changing JoinQParserPlugin
First, we will change org.apache.solr.search.JoinQParserPlugin.createParser to parse local parameter.
public QParser createParser(String qstr, SolrParams localParams,
SolrParams params, SolrQueryRequest req) {
return new QParser(qstr, localParams, params, req) {
public Query parse() throws SyntaxError {
// omitted
boolean includeParent = Boolean.parseBoolean(getParam("includeParent"));
String childfq = getParam("childfq");
if (StringUtils.isNotBlank(childfq)) {
QParser parser = QParser.getParser(childfq, "lucene", req);
childfqQuery = parser.getQuery();
}
JoinQuery jq = new JoinQuery(fromField, toField, fromIndex, fromQuery,
childfqQuery, includeParent);
jq.fromCoreOpenTime = fromCoreOpenTime;
return jq;
}
};
}
}
Changing JoinQueryWeight and JoinQueryWe need change org.apache.solr.search.JoinQuery.JoinQueryWeight.getDocSet(), before return result: filter child docs if childfq is not null, include parent docs if includeParent is true.
Also we have to change JoinQuery's equals and hashCode method to consider includeParent and childfq parameters.
class JoinQuery extends Query {
private Query childfq;
private boolean includeParent;
public JoinQuery(String fromField, String toField, String fromIndex,
Query subQuery) {
this(fromField, toField, fromIndex, subQuery, null, false);
}
public JoinQuery(String fromField, String toField, String fromIndex,
Query subQuery, Query childfq, boolean includeParent) {
this.fromField = fromField;
this.toField = toField;
this.fromIndex = fromIndex;
this.q = subQuery;
this.childfq = childfq;
this.includeParent = includeParent;
}
private class JoinQueryWeight extends Weight {
public DocSet getDocSet() throws IOException {
while (term != null) {
// keep same
}
smallSetsDeferred = resultList.size();
if (resultBits != null) {
for (DocSet set : resultList) {
set.setBitsOn(resultBits);
}
// return new BitDocSet(resultBits); changed as below:
DocSet rstDocset = new BitDocSet(resultBits);
rstDocset = postProcess(fromSet, rstDocset);
return rstDocset;
}
if (resultList.size() == 0) {
return DocSet.EMPTY;
}
if (resultList.size() == 1) {
// return resultList.get(0); changed as below:
DocSet rstDocset = resultList.get(0);
rstDocset = postProcess(fromSet, rstDocset);
return rstDocset;
}
// omitted
//return new SortedIntDocSet(dedup, dedup.length); changed as below:
DocSet rstDocset = new SortedIntDocSet(dedup, dedup.length);
rstDocset = postProcess(fromSet, rstDocset);
return rstDocset;
}
public DocSet postProcess(DocSet fromSet, DocSet rstDocset)
throws IOException {
if (childfq != null) {
DocSet filterSet = toSearcher.getDocSet(childfq);
rstDocset = rstDocset.intersection(filterSet);
}
if (includeParent) {
rstDocset = rstDocset.union(fromSet);
}
return rstDocset;
}
}
public boolean equals(Object o) {
if (!super.equals(o)) return false;
JoinQuery other = (JoinQuery) o;
return this.fromField.equals(other.fromField)
&& this.toField.equals(other.toField)
&& this.getBoost() == other.getBoost()
&& this.q.equals(other.q)
&& (this.fromIndex == other.fromIndex || this.fromIndex != null
&& this.fromIndex.equals(other.fromIndex))
&& this.fromCoreOpenTime == other.fromCoreOpenTime
&& this.includeParent == other.includeParent
&& (this.childfq == other.childfq || this.childfq != null
&& this.childfq.equals(other.childfq));
}
public int hashCode() {
int h = super.hashCode();
h = h * 31 + q.hashCode();
h = h * 31 + (int) fromCoreOpenTime;
h = h * 31 + fromField.hashCode();
h = h * 31 + toField.hashCode();
// as boolean.hashCode
h = h * 31 + (includeParent ? 1231 : 1237);
if (childfq != null) h = h * 31 + childfq.hashCode();
return h;
}
public String toString(String field) {
return "{!join from=" + fromField + " to=" + toField
+ (fromIndex != null ? " fromIndex=" + fromIndex : "")
+ "includeParent=" + includeParent
+ (childfq != null ? " childfq=" + childfq : "") + "}" + q.toString();
}
}
CaveatAs we only use this feature in single core mode, not in shards(multiple cores) mode, so we have not tested whether this works in shards mode.
References
Solr Join Query
Solr Other Parsers




 is the weight of the edge between vertices i and j, we can define shortestPath(i, j, k + 1) in terms of the following
is the weight of the edge between vertices i and j, we can define shortestPath(i, j, k + 1) in terms of the following 

 with flow capacity
with flow capacity  , a source node
, a source node  , and a sink node
, and a sink node 
 from
from  for all edges
for all edges 
 from
from  , such that
, such that  for all edges
for all edges  :
: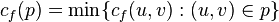
 (Send flow along the path)
(Send flow along the path) (The flow might be "returned" later)
(The flow might be "returned" later)